Identity Resolution - Why CDPs Fall Short
Learn about what Identity Resolution is, and why you should be managing this process yourselves within your data warehouse.

Andrew Jesien
May 19, 2022
15 minutes

In the world of customer data, “Identity Resolution” can be a daunting topic to get a firm grasp on. Published content across the internet is mired in marketing jargon and CDP-sponsored language that simply stokes fear, uncertainty and doubt on the subject.
In this post we’ll break down what Identity Resolution is, how we’ve observed CDPs vastly oversell and underdeliver on this promise, and why you (and your data teams) should be managing this process yourselves within your data warehouse.
What is Identity Resolution?
Identity Resolution is the process of unifying different data sets to build a single definition of your customers. Any business is likely to have customer data originating from many different places - in application databases, within your CRM and Marketing and Support tools, offline interactions, as well as behavioral events collected from your digital products directly. Deduplicating and merging these datasets to define your unique customers is an essential task towards achieving the holy grail every SaaS vendor talks about - “the single view of the customer!“
Once able to agree on a single (and complete) definition of a customer, data teams are able discover valuable insights, and equally important - align all other teams on this shared definition to improve and personalize customer experiences.
But here’s the key question you’ll hear throughout: Where should this single customer definition reside?
Identity Resolution - Across Business Models
Identity Resolution can be a very different task depending on your business model. Here are two examples to illustrate this:
- You’re a B2C company with a website and mobile app, so you’ll be focused on identity resolution for your individual users. Identifiers to consider here may include emails, device_ids, database_ids, cookie_ids, and also basic PII like name, address, phone , etc. You’ll want to answer questions like the following:
- How do you follow the journey of a user from an anonymous to a known (logged in) experience?
- How do you recognize that a user on the web is the same person on your mobile app?
- How do you join the information from your offline sales to online behavior, when all you have is name and address?
- You’re a B2B SaaS company with a “freemium” offering. Users can create one or many Workspaces, and users from the same company should all roll to one Account (for billing purposes). In this case you’ll need to define and merge data on all three of these “entities,” and this can change quite a bit based on your tech stack and business model. Because of these additional “entities,” this task is a broader effort sometimes referred to as Entity Resolution, and you may need to tackle the following challenges:
- How will you define and manage associations between Users, Workspaces and Accounts?
- How will you merge company data into single Accounts when this info comes from your CRM, free-text lead forms, freemium signups, Clearbit enrichment, and Crunchbase data? You can’t just rely on a domain name, so this will require bespoke logic specific to your setup.
Two Main Strategies
There are two main strategies that companies use to tackle Identity Resolution:
- Buy a third-party tool that stores its own “golden record” of your customers. These tools fall into the Customer Data Platform (CDP) space.
- Manage identity directly in your own data warehouse. This could be done entirely in SQL or involve third-party tools that specialize in merging data sets.
Where the Market is Headed
The explosion of the Modern Data Stack has enabled companies to efficiently leverage their cloud data warehouse as a central hub and single source of truth for customer data. By adopting this model, there’s been a rapid shift towards companies preferring to do identity resolution in the warehouse, and realizing much more value when choosing this strategy. Compared to off-the-shelf CDP solutions like mParticle, Segment, Tealium, and Simon Data, the tooling for identity resolution within the warehouse is far more flexible and robust, and it empowers data teams to align their analytics with how they then operationalize and distribute data to the rest of the business.
Put simply, we believe this data modeling task is one of the few things that data teams should be owning in-house. Customer definitions will inevitably become bespoke for each business, and these models become the engine that then powers all of the analytics, decision making and orchestration that sits on top.

CDPs force their customers to adhere to strict entity relationships, limited customization and data manipulation, and blackbox identity resolution. Companies are not built on simple data and processes. We live in a complex world where business models, customer journeys, and go-to-market motions cannot be accurately represented by these inflexible schemas. By centralizing and transforming your data with a warehouse-first approach, you allow the individuals that know the inner workings of your business to build your data activation framework.
Rachel Bradley-Haas
Co-Founder
•
Big Time Data
CDP Limitations for Identity Resolution
Many of us here at Hightouch came from the cloud CDP space where we saw hundreds of companies trying to solve identity resolution using an off-the-shelf CDP - it’s always a headache. To be more specific, we’ve observed the following significant limitations when companies rely on CDPs for Identity Resolution:
Incomplete - CDPs often only have access to the behavioral event data collected within your digital products, and fail to consider all the other datasets across your business: within your internal databases, other SaaS tools, and offline sources, etc. How can your customer identity be complete if it’s only based on a fraction of your data?
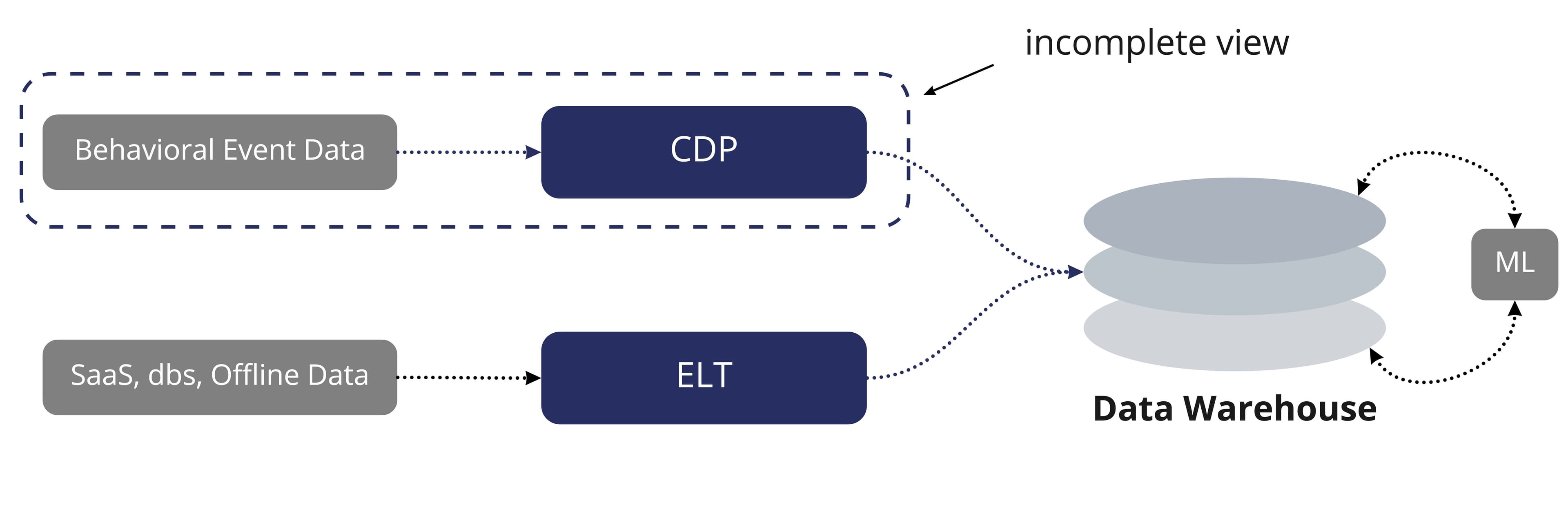
Inflexible - Cloud CDPs enforce a proprietary data model to represent the “User” profile. While this may be helpful to get up and running quickly for simple online-only B2C businesses, these tools immediately struggle when you need to represent anything other than individual users. Pulling from our B2B example above, CDPs will not have the flexibility to manage Workspaces and Accounts, especially when there is a tiered hierarchy and you’re looking to manage associations between them. What if a user belongs to two accounts? What if an account is a subsidiary of another account? What if your data doesn’t fit the data model the CDPs defined for you?
- Additionally, even in B2C business models, you’ll often want to associate Users with other entities (such as Subscriptions, IoT Devices, Memberships, Trading Accounts, Courses, etc.), and managing these many relationships is nearly impossible within a tool that enforces its own proprietary data model.
Locked up - There’s often no easy way to export the merged identities within a CDP directly to the data warehouse. Believe it or not, it’s actually quite common that data teams perform their own identity resolution in the warehouse anyways (at companies that already pay for a CDP)! An accurate and complete definition of the customer has to be in the warehouse to then answer important questions around usage, attribution, and engagement. Without direct access to your customer identities, it becomes impossible for data teams to do any deeper analysis themselves.

Brittle - If you ever need to make changes to the identity configuration within a cloud CDP, you cannot do this after live data has been flowing through. There is no undo or unmerge button. In most cases to fix a historical mistake there is no option but to completely axe the whole instance, reconfigure settings, and then reload all historical events into a new instance of the CDP. This is time-consuming, requires a ton of help from the CDP support team, and also requires you to recreate all the trait/audience build that you already had in the previous instance.
Independent from event stream - Events that are collected and then flow over to destinations within a CDP do not natively consult the identity graph for enrichment on the way over. This is a very common misconception, and it requires a lot of hacked-together loops with lambda functions to actually enrich events with info (or identifiers) from the CDP-managed ID graph.
Deterministic-only - Almost all CDPs will only support deterministic matching, meaning they will only support merging on identifiers that uniquely define a customer. For simple eCommerce companies this may be ok, however many times your data sets involve free-text entered names, addresses, or phone numbers and you’ll get into situations where you need to explore probabilistic merging that involves “fuzzy” matching, usually based on confidence scores. This type of intelligence is not typically supported within CDPs.
The “Real-Time” Promise - This is a very important and widely misunderstood topic. Many CDPs market themselves as tools that manage identities in “real-time.” While this phrase sells really well, our experience has shown us two things:
First, only an extremely small fraction of CDP use cases actually demand real-time identity computation. To put this more bluntly, you probably don’t need this. Although low-latency use cases are very real in the CDP world, they typically involve just the event streaming “CDI” capabilities of the tools, by simply communicating an event to some downstream system or tool. For example, to immediately send an Order Confirmation email a few seconds after a purchase, you’d simply instrument an event with with the email of the user and context of that purchase. This event streaming to an email API does not involve an identity graph on the way over.
Note: If you do have an example where real-time identity is crucial for your CDP use case, I want to hear about it! Please email me at andrewjesien@hightouch.com to brainstorm (my hunch is that there’s likely a better and more purpose-built technology to plug in for your use case, due to point 2 below...)
Second, for the rare use cases where real-time identity compute is required, cloud CDPs fail to meet expectations. If you need identities resolved in a matter of seconds, we strongly encourage you to ask the following questions from your CDP vendor during evaluation:
- “What is your SLA for real-time Identity compute?”
- “What is your end-to-end compute latency (for a new data point to arrive, merge to a profile, and be available for retrieval)? Is this backed by an SLA? What is the p90 for this? 20 seconds? 1 minute? 5 minutes? 10 minutes? 30 minutes?”
- “Do you publish these SLAs?” “Where?”
Note: To be clear, we are not saying that the alternative is faster. Computing identity within the warehouse will have latencies related to how often data is being loaded to the warehouse. This being said, cloud data warehouses are getting much faster (Snowflake and BigQuery already support streaming inserts), and we encourage you to closely evaluate your use cases, performance requirements, and consider the related costs and limitations mentioned above.
Warehouse-First Benefits for Identity Resolution ✅
Some benefits of managing Identity Resolution directly in the warehouse:
- Comprehensive - The data warehouse will contain all the other data (outside of only clickstream events) that comes from other ETL pipelines - from internal databases, SaaS tools and offline interactions. Many times the most important and valuable insights come from these customer touchpoints, so it’s imperative that your profiles are as complete as possible.
- Infinitely flexible - With the power of SQL and relational data, you have the full flexibility to represent anything you want within a warehouse. You can build the most accurate and robust User definition, but then also represent any other entity that is specific to your business and its relation to your individual Users. As your business evolves over time, this flexibility also allows you to constantly improve your models as new data sources are introduced. You can manipulate and merge anything you want, you can introduce and test probabilistic methodologies, and you can test out any open source projects on your data sets without ever being limited by the tooling of a SaaS vendor.
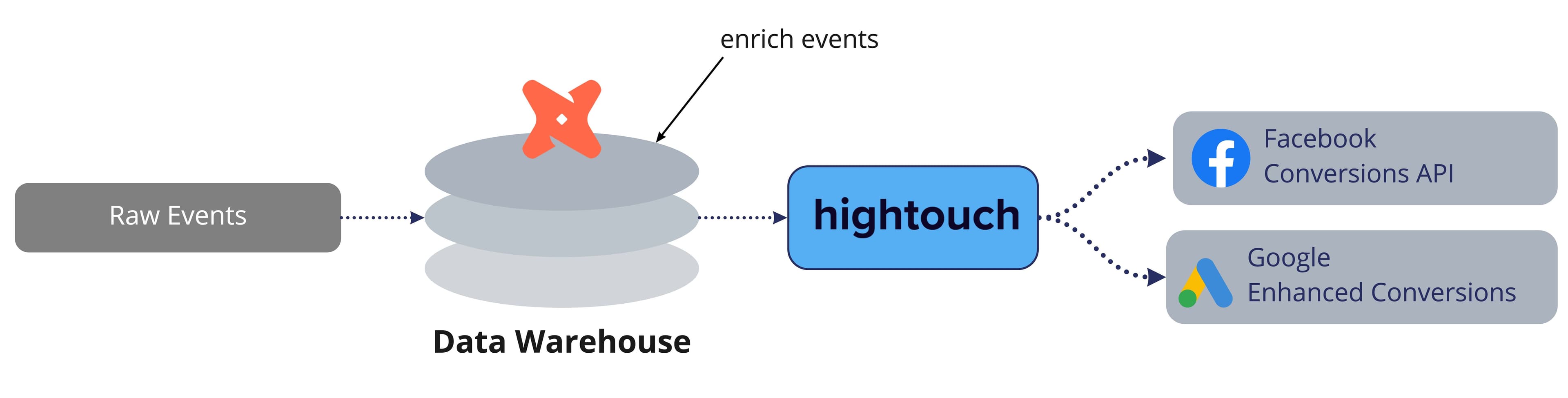
- Enriched - At Hightouch, our customers are many times preferring to load “raw events” directly into the warehouse, to then be enriched with additional identifiers or related metadata (not available in the event stream at time of capture), before forwarding onto a final destination. This is especially valuable for pushing events to “Conversion” endpoints like the Facebook CAPI or Google’s Enhanced Conversions directly from the warehouse, as you’ll achieve much higher match rates with enriched identifiers from your own identities table. Read more on this here!
- Future-proofed - Tooling around the warehouse is exploding (just google “the Modern Data Stack”) and will only continue to improve. Working from the warehouse allows you to reap the benefits of this data ecosystem, vs. being locked into the limited tooling within a CDP vendor.
- Secure - Managing customer identities in your own private cloud greatly reduces your footprint for security risk. You won’t have a third party storing your data, and you’ll have the enterprise-grade controls provided by modern cloud platforms to control and govern access. This will only become more critical as data privacy regulations mature and demand more regionalization and stewardship.
- Related: There is a specific reason the majority of off-the-shelf CDP vendors refuse to sign BAAs for HIPAA Compliance (to manage healthcare data). By the nature of their architecture, CDPs have too many threat vectors to assume the liability/risk to safely process and store clinical info. This limitation does not exist when leveraging your own data warehouse.
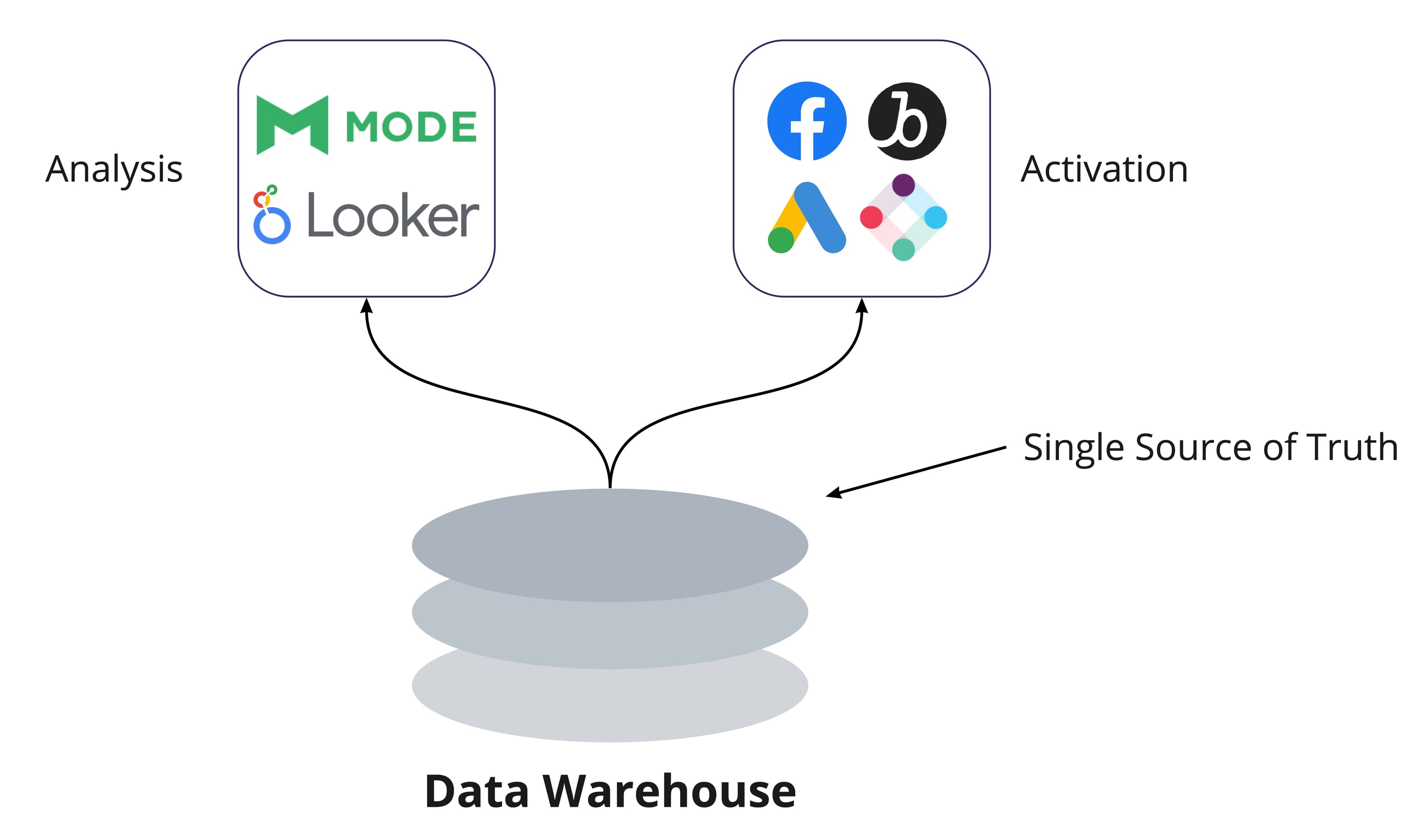
- Single Source of Truth - When the definition of your customer lives in the warehouse, all teams can be aligned across the entire business. Your BI reports will actually match the definition of customers reflected in other tools! The feedback loop between analytics and activation becomes immediate, since they’re now driven from the exact same underlying models.
Basic How-To
Taking on Identity Resolution in-house can sound intimidating, and it’s worth noting that for more advanced needs with large and varied data sets, there are third-party tools that focus on merging identities in a warehouse that leverage ML tech. If you have complex needs and don’t have the resources to take this on in-house, it may be worth checking out the three options below:
- Hightouch - Our Identity Resolution feature offers a code-free rules-based editor that allows users to resolve multiple identity and entity graphs directly within any data warehouse.
- Zingg - Open Source solution for entity resolution that works natively on the warehouse (on the data type and model of your choice), without much preprocessing or data cleansing. Here are two recent posts on using Zingg within Snowflake and Databricks, respectively.
- Truelty - Designed for Snowflake and large B2C organizations, Truelty automatically generates the code to natively process deduplication within your Snowflake instance. Typical use cases involve cross channel, cross app, and anonymous to known identification.
If your organization instead opts to develop in-house method using just SQL, our recommendation is to start simple and focus first on your highest-value data sets. We walked through a basic example of this SQL logic in our earlier blog post titled Identity Resolution in SQL.
First you’ll need to collect and replicate data from all the places customer data is generated into the data warehouse. For this process of data ingestion we recommend best-in-breed tools Snowplow (for event collection) and Fivetran (for ELT). Note, each of these vendors invest heavily in helping organizations adopt best practices for data modeling within the warehouse (see here and here, respectively).
Once data is loaded into a warehouse, it’s common for data teams to model datasets into single “source of truth” dimension tables that represent each “entity” within the business, and then manage the process to keep these up to date. To help manage this transformation process at scale, many businesses are turning to dbt, the hottest modeling tool in data today. dbt simplifies transformation within the warehouse, as it allows analysts to transform data with just SQL, but do so in a way that empowers them to collaborate, test, and continually abstract the complexity away from the (otherwise) hairy dependencies that can arise throughout.
Pairing these final customer dimension tables with Hightouch, you have the two fundamental building blocks that actually deliver on the promise of CDP:
- One place for all teams to agree on “the single view of the customer” (models in the data warehouse)
- A way to keep this definition synced everywhere else (Hightouch!)
Bringing it Home
Identity Resolution is the task of aggregating all the information you have and answering the following question: “Who is my customer?”
Historically off-the-shelf CDPs used to be the only accessible option for identity resolution, but with the boom of the Modern Data Stack (and products like Hightouch's Identity Resolution feature), there’s a new sheriff in town. By cultivating your own definitions in your data warehouse, you’re able to build much more complete, accurate, and secure customer models that will pay dividends far beyond the typical CDP value props around personalized email and advertising. These models will directly and continually power everything data-driven across your business moving forward.
For more info on our predictions for CDP, check out cdpsaredead.com









