Syncs declare how you want query results from a model to appear in your destination.
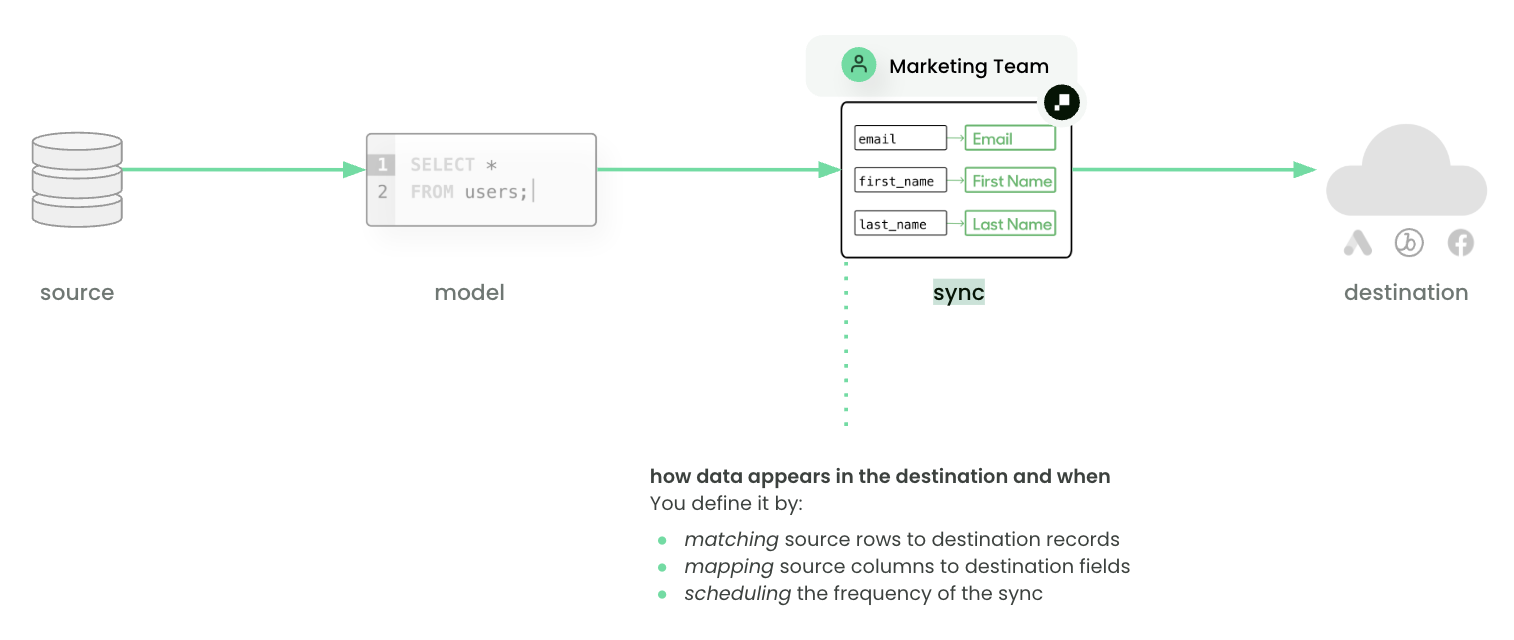
To learn more about syncs on a conceptual level, see the core concepts page. Refer to destination docs for specific configuration details.
To learn more about the information the Hightouch UI displays on your syncs and what actions you can take from the UI, continue to the following sections.
Syncs overview page
Hightouch displays all syncs, both active and inactive on the Syncs overview page.
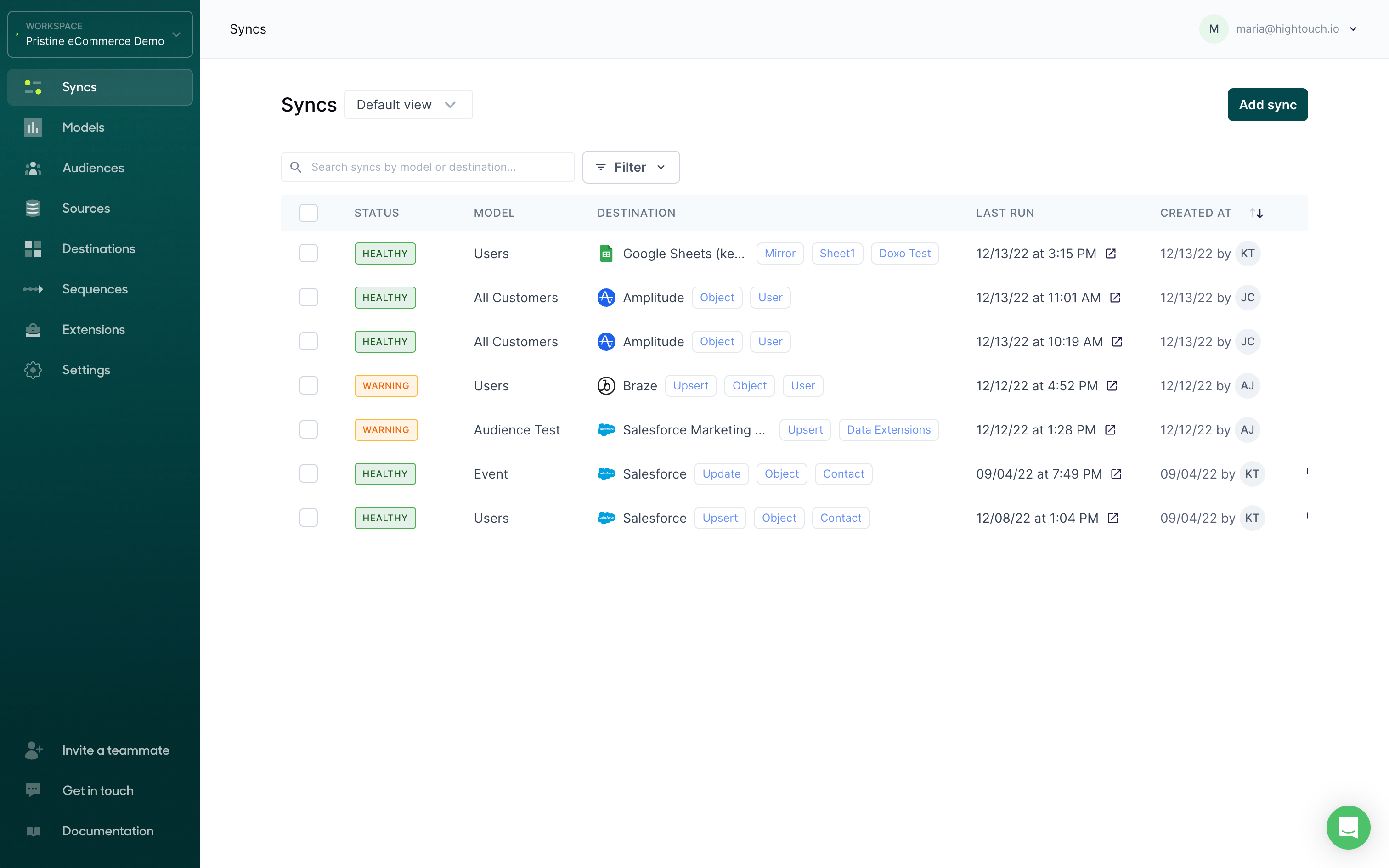
For each sync, the overview shows:
- The sync's status
- The sync's associated model
- The sync's associated destination
- The date and time, in your timezone, of the sync's last run
- The date the sync was created at, and who created the sync
You can view more in-depth information for any sync by clicking on it. This takes you to that individual sync's overview page.
Sync status
Your sync's status is based on the latest information available on a run:
- Healthy: a recent run completed
- Pending: no runs have been scheduled yet
- Disabled: the sync has been turned off
- Querying: the sync is querying its associated model
- Preparing: the sync is preparing data to send to its associated destination
- Queued: the sync is scheduled to begin writing to its destination
- In Progress: the sync is writing to its destination
- Incomplete: the sync had a temporary interruption and will resume in a new run
- Aborted/Failed: there was an error in the sync progress—check the errors on the sync to see why the sync failed
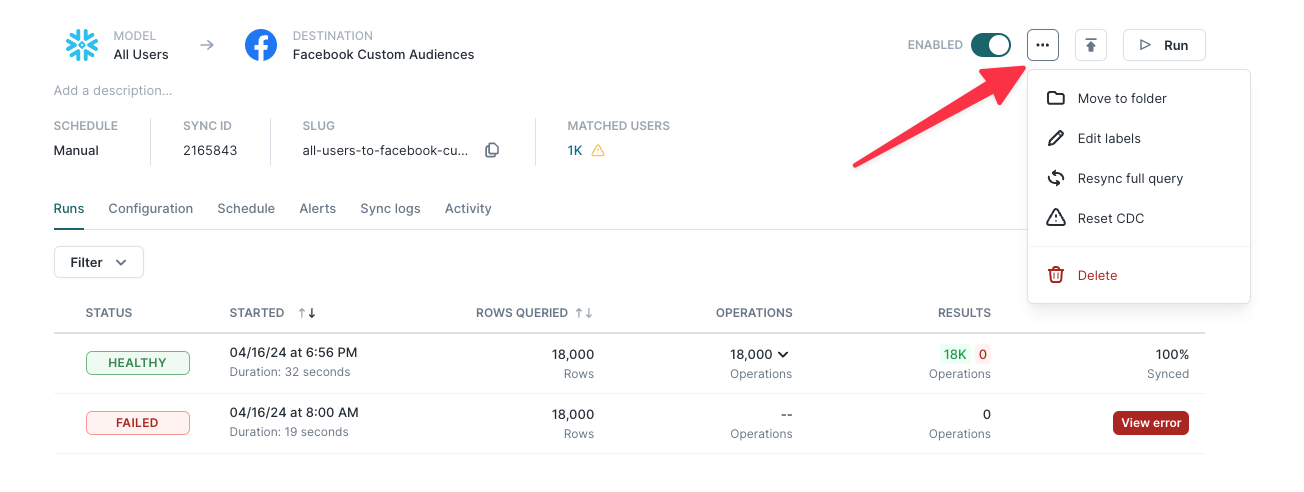
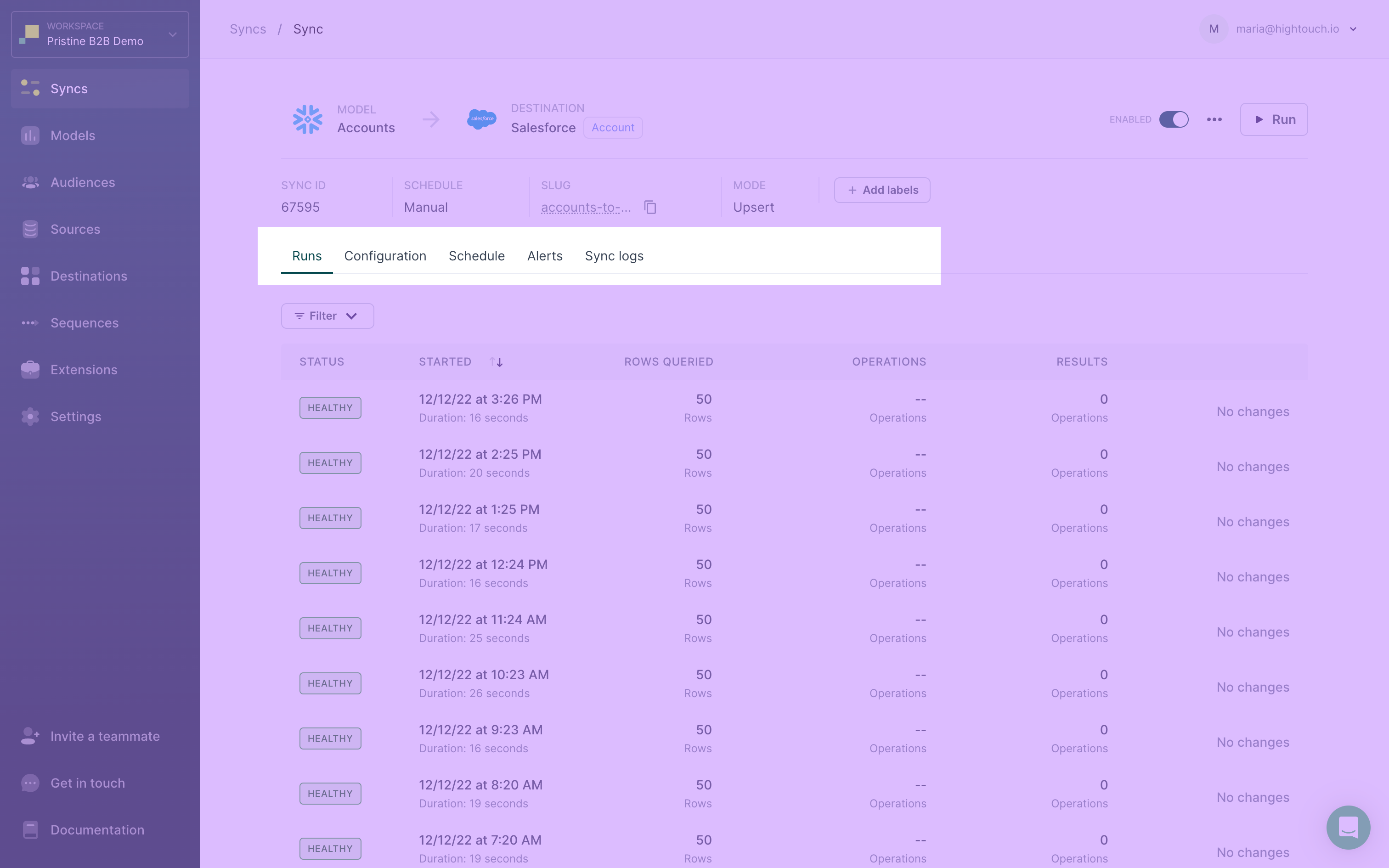
Individual sync overview page
You can view an individual sync's information by clicking on it on the on the general Syncs overview page.
A particular sync's overview page shows general information, including:
- The sync's associated model and destination
- Whether the sync is currently enabled or disabled
- The option to manually Run the sync
You can also choose to move the sync to a folder, edit its labels, resync the full query results of a model, reset change data capture, or delete a sync from here.
The overview page also shows more specific information including:
- Sync ID: a numerical unique identifier for the sync that is necessary when setting up an Airflow operator, or using the Dagster, Prefect, or Mage extensions
- Sync schedule type: manual, interval, custom, cron, dbt Cloud-, or Fivetran-triggered
- Sync mode: this only appears if there are multiple sync mode options, see the sync mode docs for more information
- Match rate: this only appears if the sync is to a paid advertising destination, see the match rate docs docs for more information
- Any associated labels: see label based access-controls for more information
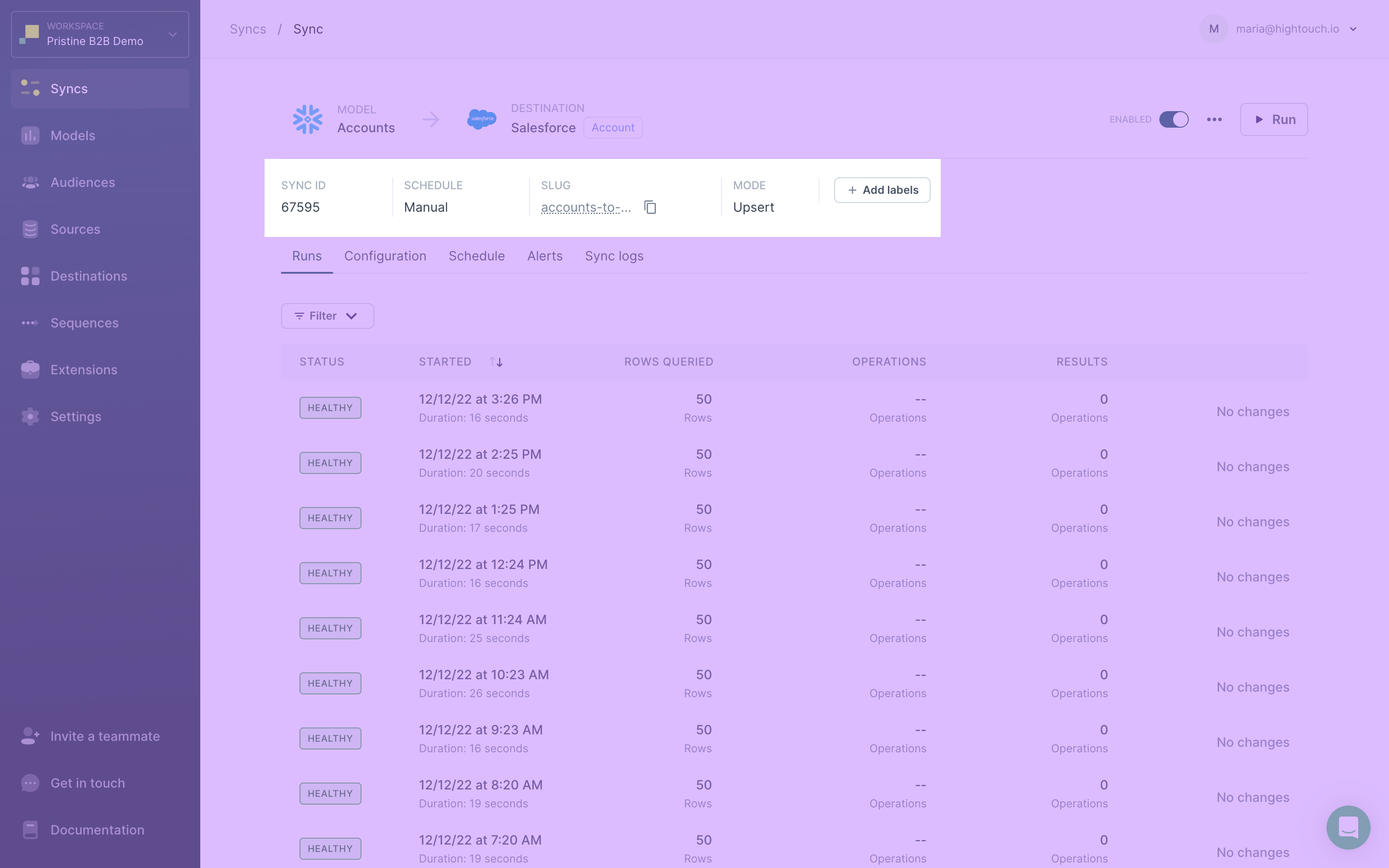
Finally, you can click the tabs on the overview page to view and edit settings:
- Runs: You can see the status, time, and more details from the most recent runs. Selecting a particular run brings you to the live debugger.
- Configuration: You can view and edit the sync's configuration.
- Schedule: You view and edit the sync's run schedule.
- Alerts: You view and edit the sync's alerts.
- Sync logs: You can view and edit where your sync's historical logs are stored.
- Activity: You can view recent changes to the sync configuration and other settings
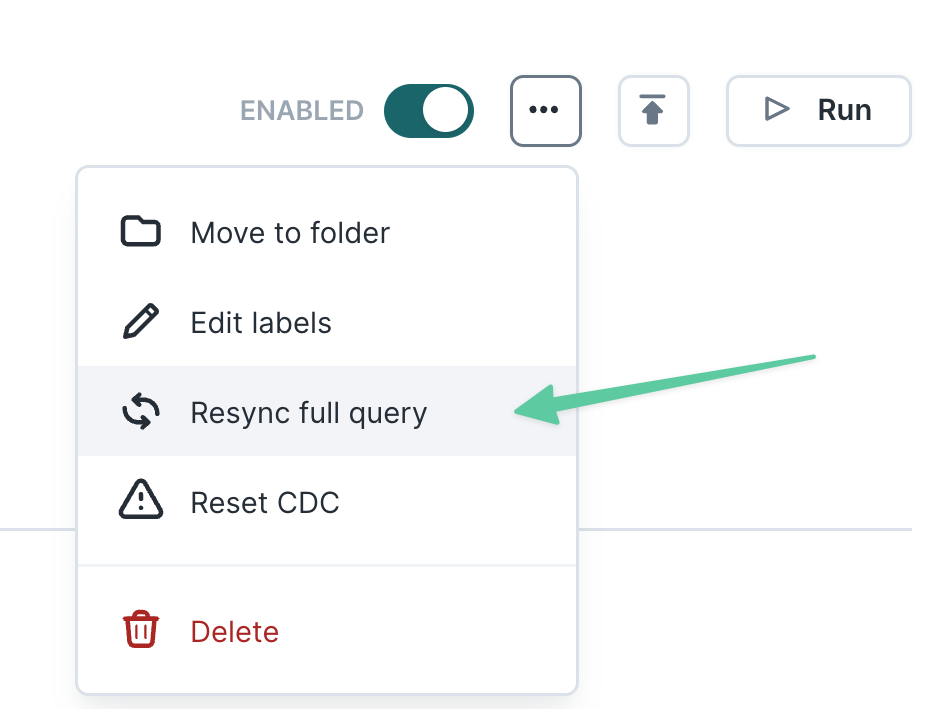
Resync full query
By default, Hightouch keeps track of changes to your data between syncs and only sends necessary updates. Therefore, an initial sync run often shows that many records were Added. Subsequent runs often show fewer records Added, and instead show that many records have Changed or Removed.
If you wish to reset the sync's tracking to its initial state—as if it were syncing for the first time again—you can select Resync full query from the menu on the sync's main page. Before you do, make sure that your sync meets the prerequisites to safely do so.
Full resync prerequisites
Full resyncs process all rows that currently exist in the model as Added rows. Check the following before triggering a full resync:
| Criteria | Explanation |
|---|---|
| Sync mode |
|
| Delete behavior |
|
Resyncing the full query could create duplicates or other issues in your destination data if the prerequisites above haven't been met.
Clear and fill
If the destination supports removing all records in a segment or audience, this option will become available. This resync mode is similar to a full resync mentioned above with an additional preprocessing step. Before processing all rows that are currently in the model, the segment/audience selected in the sync configuration will be cleared of all users/identifiers.
Reset CDC
If you want to reset change data capture without resyncing records, you can select the "Reset CDC" option instead.
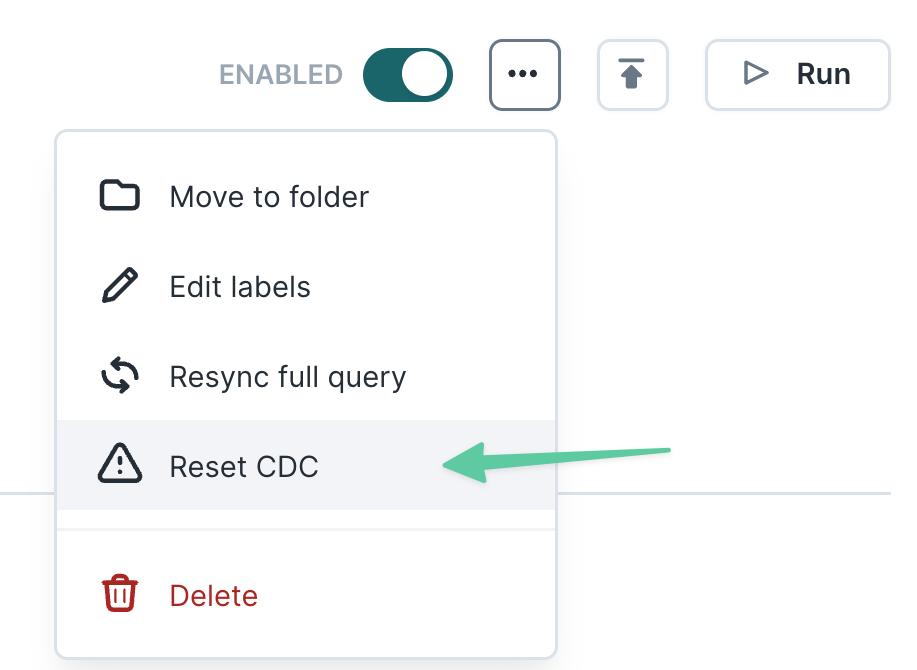
This instructs Hightouch to ignore the current state of your model and to track only rows that are added, changed, or removed in the future. The next sync run will be used as an opportunity to capture a snapshot of your model, but no data will be sent to the destination. Thereafter, future sync runs will track new changes only.
The "Reset CDC" option is recommended for insert-only use cases like conversion events, operational alerts, and other situations where a backfill would create undesired duplicate records. Beware that skipping the backfill may cause your destination to drift out of sync with your data model.
Run details
When viewing a specific sync, you can inspect detailed run-level information. A run is a particular invocation of a sync, either triggered manually or scheduled.
Each run provides:
- The particular run's status
- The time the run started and its duration in seconds
- The number of rows queried
- The total number of operations, including rows added, changed, removed
- The results—the total number of successful operations in green and the number of rejected operations in red
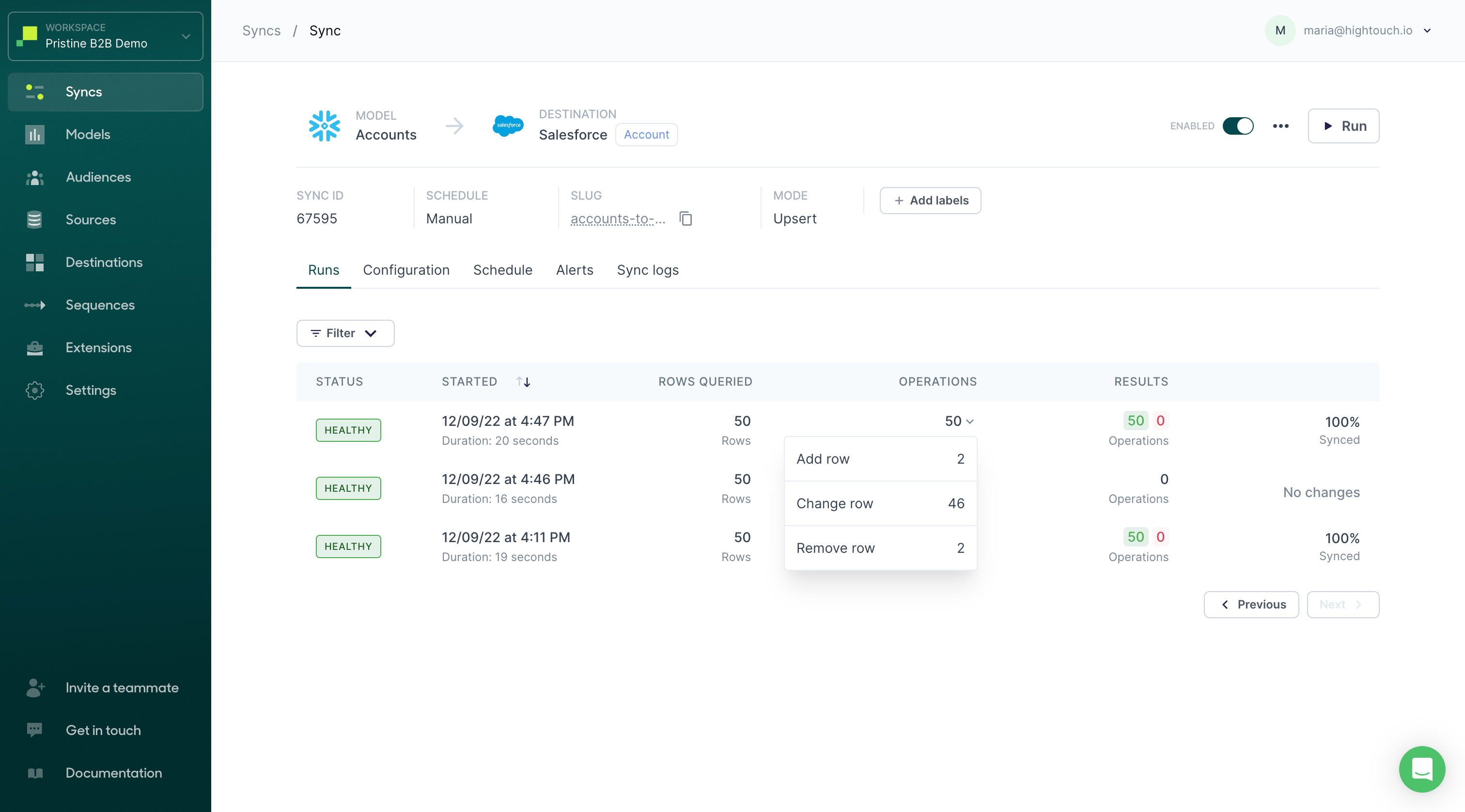
If there were any errors, you can click the View Error button to view details related to the run.

Configuration
The configuration section exposes destination-specific configuration options. While sync configurations vary depending on the destination, they generally include:
- Type: What data type to sync to in your destination; for example, objects, events, subscription lists, etc. To learn more, see sync types and modes.
- Mode: What update mode to use; for example, upsert, insert, update, etc. To learn more, see sync types and modes.
- Record matching If updating or upserting, how rows in the source should be matched to records in the destination. To learn more, refer to the record matching docs.
- Field mapping: What columns from your source should be synced to the destination, and what destination fields they should appear as. To learn more, refer to the field mapping docs.
- Batching: How data should be batched in API requests.
- Delete behavior: What to do when a record leaves your source—in other words, when your model no longer returns a record that was returned in the previous sync run.
Delete behavior
For some sync types and destinations, you may want to delete records if they no longer appear in your model's query results.
For example, you may be syncing customer records to your CRM based on a model that queries all active users from your data warehouse. If some users become inactive—in other words, they no longer appear in your model's query results—you may want to delete them or some information about them from your CRM.
Depending on the destination and sync mode, these are common options for delete behavior:
| Behavior | Description |
|---|---|
| Do nothing | Preserve the record in the destination. This option is useful for when you want your destination to continually accrue records from your source. |
| Clear fields | Keep the record, but clear the mapped fields. This option useful to retain records in your destination, but clear the fields that are mapped in your sync. |
| Delete destination record | Delete the record in the destination. This option is useful for when you want your destination to exactly mirror your source by dropping records that have dropped out of your model. |
Hightouch only acts on records as they leave your model's query results, and after you apply deletion settings. Hightouch doesn't have access to historically removed records, so syncs can't delete records or clear fields that have already been removed from your source. Hightouch only deletes records that left your source in comparison to the immediately previous run. A full resync doesn't delete or clear historically removed records.
Regardless of the option you choose for delete behavior, a sync run's detail page always displays removed rows.
Check out the particular destination's documentation for its delete behavior configuration details.
Configuration actions
When working with a sync configuration, you can also choose to test a row or edit the configuration as a JSON object.
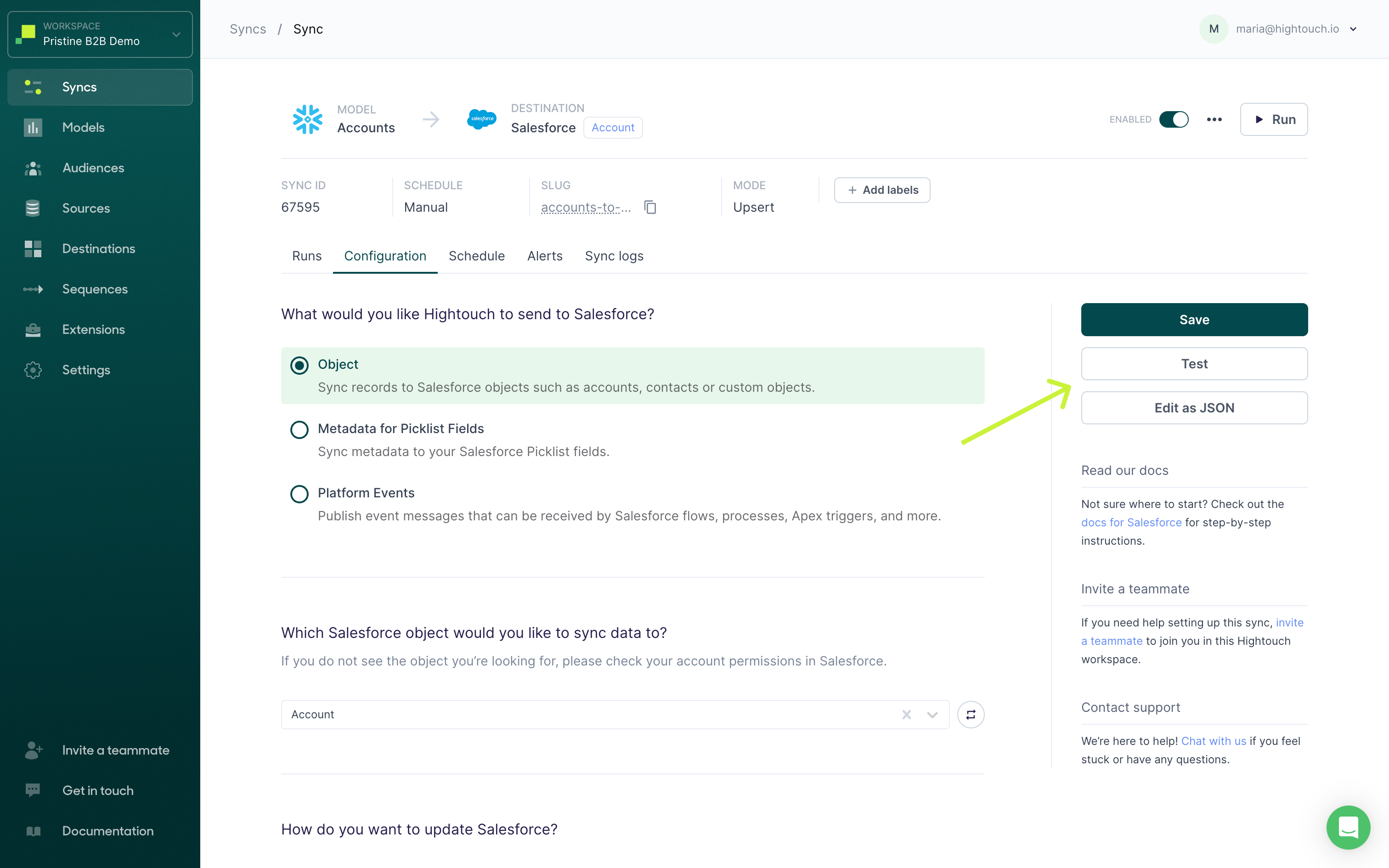
Test a row
You can test a sync by sending just one row from your model to your destination. This lets you verify that the sync is working as intended before initiating a run of your entire sync.
From your sync's configuration page, click Test and select a row to sync. Before testing a row, you can edit the columns’ data types and values by hovering over them. Click the pencil icon, make your edit, and then click the check mark to save any changes. Editing the model column used for record matching is not supported since Hightouch intentionally strigifies it for enhanced performance.
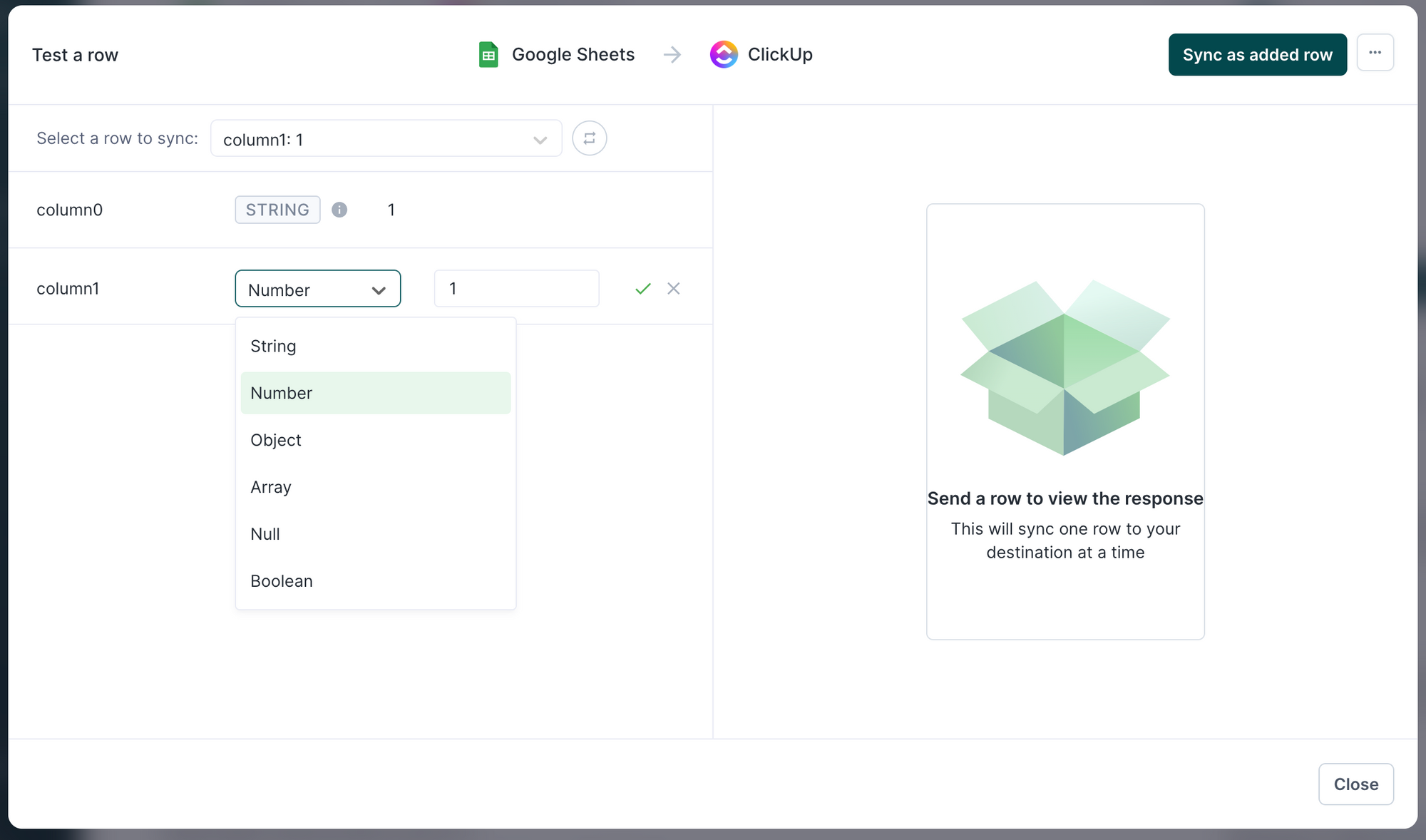
The row testing window only displays certain data types, such as string and number. If a model contains a column with a different type, such as date, the UI displays the type as string. This only concerns the UI—Hightouch doesn't convert the data type to string when syncing data. To confirm a column's data type, refer to its type on the model configuration page.
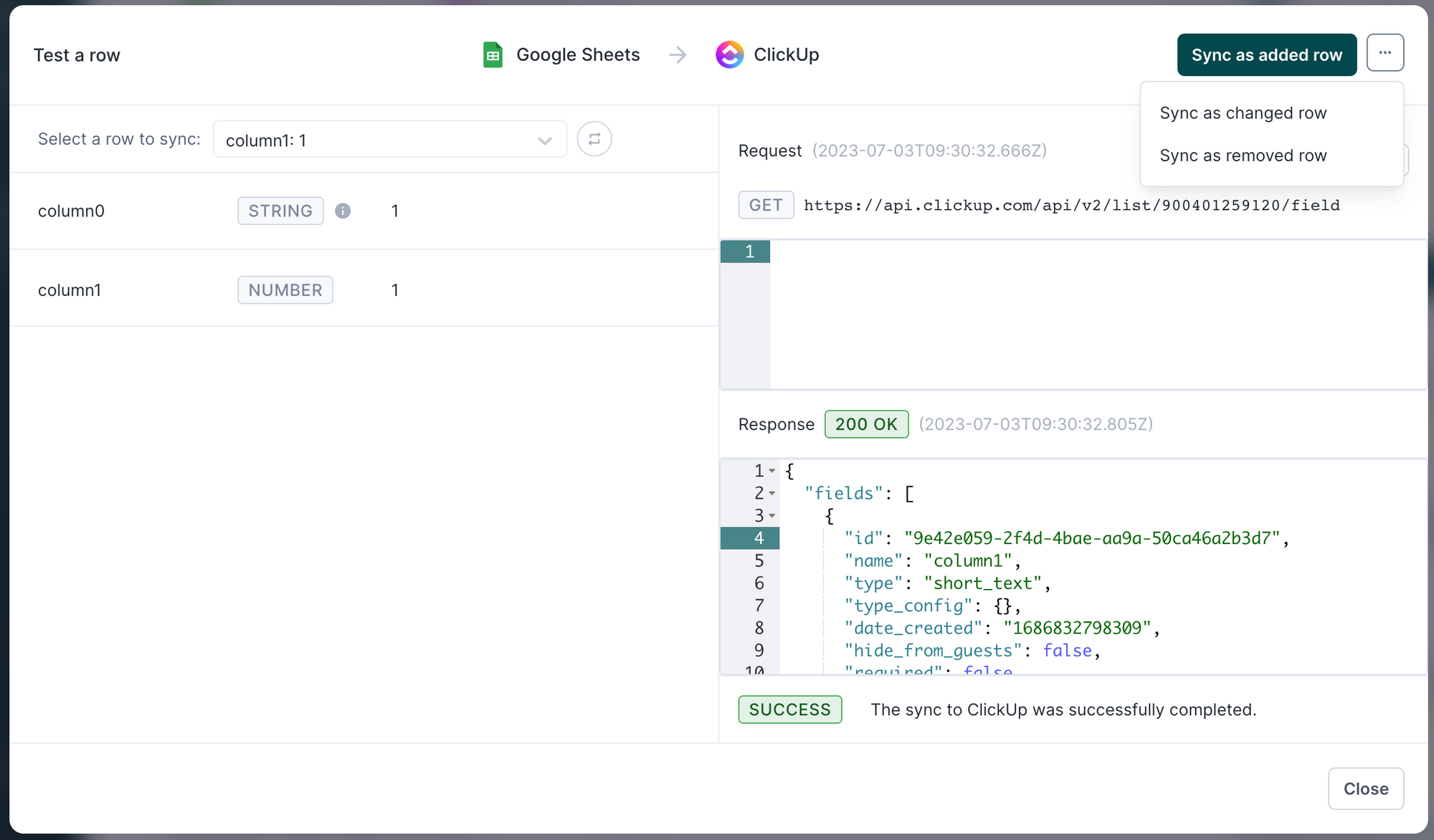
You can then decide to sync the row as an added, changed, or removed row and observe the API requests and responses. The UI might take a few seconds to update before displaying the results.
Edit as JSON
You can edit your sync's configurations as JSON code to quickly make multiple changes or copy and paste one sync's configurations to another.
For example:
{
"mode": "upsert",
"type": "object",
"fromId": "track_visitor_id",
"object": "user",
"mappings": [
{
"to": "uuid-western",
"from": "uuid"
},
{
"to": "Trialer Status",
"from": "trialer_status"
}
],
"customMappings": [
{
"to": "unique_notification_status",
"from": "notify_status"
}
]
}
Schedule
Part of sync configuration is deciding how frequently the sync should run. Besides triggering syncs manually, you can schedule syncs with these options:
- Interval: You can schedule your sync to run on a set interval, for example once every day.
- Custom recurrence: You can schedule your sync to run a specific date and time, for example every Monday at 9 AM.
- Cron expression: You can schedule your sync using a cron expression.
- dbt Cloud: You can trigger syncs automatically via dbt Cloud.
- Fivetran: You can trigger syncs automatically via Fivetran.
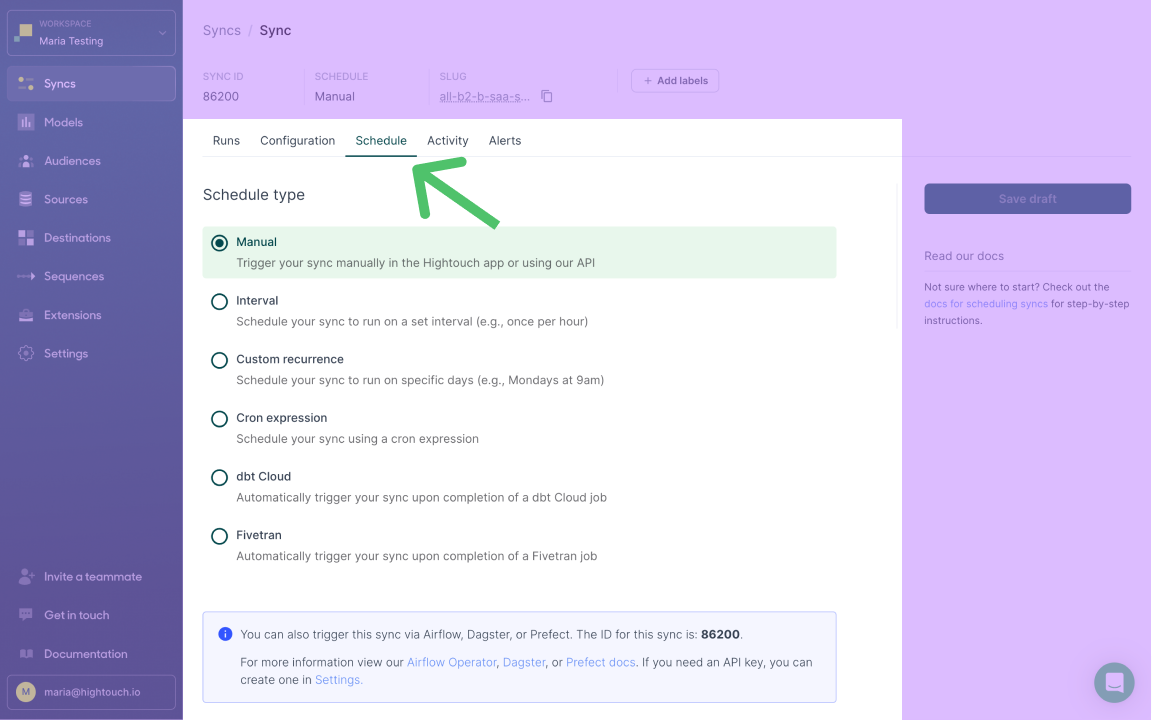
Though not listed as schedule options, you can also trigger syncs using Airflow, Dagster, Prefect, Mage, or the REST API. To learn more about your scheduling options, refer to the sync scheduling page.
If you have dependencies between syncs, for example you require one sync to complete before another begins, sync Sequences can help you manage scheduling.
Alerts
You can configure alerting on a per-sync basis from this section.
Sync logs
You can configure Warehouse Sync Logs from this section. This feature writes information on the results of your syncs back into your warehouse so that you can perform more complex analysis.